论文
Distilling Task-Specific Knowledge from BERT into Simple Neural Networks
1 介绍
2 相关工作
模型压缩 一项突出的工作致力于压缩大型神经网络以加速推理.早期的开创性工作包括LeCun等人(1990),他们提出了一种基于局部误差的方法来修剪不重要的权重。最近,Han等人(2015)提出了一种简单的压缩pipeline,在不损害精度的情况下,实现了模型尺寸的40倍缩小。不幸的是,这些技术导致不规则的权重稀疏,这排除了高度优化的计算例程。
3 文章的工作
3.1 模型结构
教师模型采用预训练微调的BERT,对于输入的句子对,通过BERT计算一个特征向量$h$,在$h$的基础上构建任务分类器。对于单一句子分类,直接构建softmax层,预测概率为$y^{B}=softmax(Wh)$,$W \in \Bbb{R}^{k \times d}$是softmax的权重矩阵,$k$为标签数量。对于句子对任务,拼接两个句子的BERT特征向量送进softmax层。在训练过程中,我们利用交叉熵损失最大化正确标签的概率,联合微调BERT和分类器的参数
相比之下,我们的学生模型是单层的具有非线性分类器的BiLSTM。将输入词嵌入输入BiLSTM后,将每个方向上最后一步的隐藏状态拼接,输入带有ReLUs的全连接层,该层的输出再传递到softmax层进行分类.
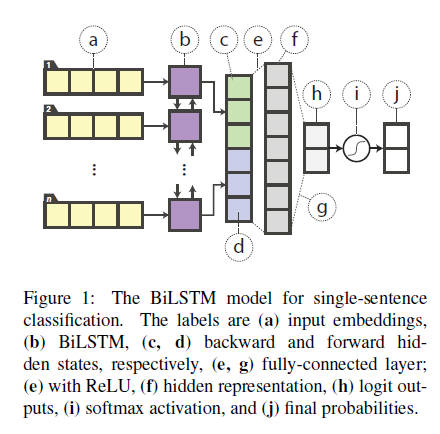
对于句子对任务,在两个句子编码($h_{s1}$和$h_{s2}$)的连体结构中共享BiLSTM的编码器,如下图所示
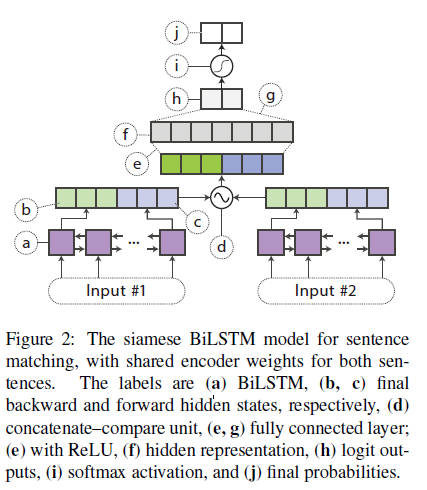
然后对两个句子向量应用标准的concatenate–compare操作$f(h_{s1},h_{s2})=[h_{s1},h_{s2},h_{s1} \odot h_{s2},|h_{s1}-h_{s2}|]$,$\odot$表示按元素乘法。然后把该输出送到ReLU激活的分类器中。
应该强调的是,为了重新审视BiLSTM本身的表示能力,约束了工程实现。我们避免了任何额外的技巧,比如注意和层归一化。
3.2 蒸馏目的
给定数据,学生模型模仿教师模型的输出。除了最后的标签,教师模型的预测概率同样重要。在二分类情感分析中,一些句子具有较强的情感属性,一些句子则是中性的。如果只用最后的预测标签训练学生模型,会丢失不确定性预测的有价值信息。softmax的参数认为是logits。学生模型在logits上训练使得训练更容易,因为教师模型在所有目标上学到的关系是同等重要的。
使用MSE损失实现$\mathcal{L}_{distill} = ||z^{(B)}-z^{(S)}||_2^2$,$z^{(B)}$和$z^{(S)}$分别是教师模型和学生的logits.交叉熵损失其实也行,但是本文实验证明MSE更好一点。
训练损失:
$\mathcal{L}=\alpha \cdot \mathcal{L}_{CE}+(1-\alpha) \cdot \mathcal{L}_{distill} = -\alpha \sum_{i} t_i \log {y_i^{(S)}} - (1 - \alpha)||z^{(B)}-z^{(S)}||_2^2$
其中$t$是ground_truth_label。对于没有标签的数据,预测label使用教师模型预测的label,即$t_i=1$如果$i=\operatorname{argmax} {y^{(B)}}$否则为0
3.3 数据增强
利用教师提供的伪标签(pseudo-labels),用一个大的、未标记的数据集来增强训练集,以帮助有效地提取知识。具体来说,随机执行以下操作:
masking:给定一个概率$p_{mask}$,随机用toekn [MASK] 代替,对应于我们的模型中的未知标记和BERT中的掩码字标记.文章认为该工作能阐明每个词对标签的贡献。
POS-guided word replacement,给定一个概率$p_{post}$,将该单词替换为相同词性(POS)的标签。为了保证原始训练分布,新单词从由词性 (POS) 标签重新归一化的一元词分布中采样。例如将 “What do pigs eat” 替换成 “How do pigs eat”。
n-gram sampling:给定一个概率$p_{ng}$,在 1-5 中随机采样得到 n,然后采用 n-gram,去掉其他单词。这个规则在概念上等同于去掉示例中的所有其他单词,这是一种更激进的屏蔽形式。
流程如下:给定一个训练例子{$w_1,…w_n$},迭代单词$w_i$制uniform distribution,如果$x_i<p_{mask}$,对$w_i$进行masking操作,如果$p_{mask} \le x_i<p_{mask}+p_{pos}$,则进行POS-guided word replacement,这两种操作是相互排斥的,即一旦应用了一条规则,另一条就会被忽略。遍历单词之后,在整个合成的例子中采用n-gram采样。这个最后合成的例子加入到增强的无监督数据集中。
对单一样本进行n次迭代处理生成n个采样结果。对于句子对任务,我们通过只增强第一个句子(保持第二个固定值)、只增强第二个句子(保持第一个固定值)和两个句子进行循环。
4 实验设置
使用$BERT_{LARGE}$作为教师模型,加载预训练权重并遵循原始、特定任务的微调。文章微调是,选择用Adam优化器并设置学习率为{2,3,4,5}*$10^{-5}$,然后选择验证集上效果最好的模型。
学生模型,将原始数据及合成数据送给教师模型预测获得预测标签(soft logit targets),用以蒸馏$BiLSTM_{SOFT}$,即设置$\alpha = 0$,这种效果是最好的。
4.1 数据集
SST-2,MNLI,QQP
4.2 超参
看论文吧
5 结论
效果比不上大模型,但是比原始的LSTM好,相对大模型就是参数少,响应快。文章认为较浅的bilstm对自然语言任务的表达能力比之前认为的更强


